
How to Learn a Language like Google
Full disclosure: This post contains affiliate links. ?
Time for another guest post from Fluentin3months' most active contributor (other than me, Benny)… Idahosa Ness of mimicmethod!
Today he gives us insight into how speech recognition works, and how we can take a leaf out of Google's speech recognition methods (which as an Android user, I can confirm are pretty spot on, even for an Irish accent!) and shares with us an excellent Kickstarter that he has running based on mixing his audio based learning methods with Duolingo's database of sentences! If anything, his super fast multilingual rap at the start of the video is worth visiting the Kickstarter page alone!
Over to you Idahosa:

You can learn a lot about how language works by studying how software-engineers approach the challenge of speech-recognition. In the early days of the field, engineers theorized that getting a computer to recognize speech was merely a question programming a large database of word recordings into it. For example, get a speaker to say the phrase “I can't wait to watch this Kickstarter video!”, and the machine would be able to link the phrase with the sounds from its database and tease out the component words:
“I…can't…wait….to…watch…this…kick…starter…video…”
Made sense in theory, but in practice things didn’t work out quite so well. Engineers would input spoken phrases, and the machine would output complete gibberish:
“again…way….to…watches…kid…star…video…”
At first, the engineers attributed the problem to a lack of variation in the word database. People speak with slightly different accents, and even the same person will pronounce the same word differently depending on context. So for each word in the database they expanded the list of possible pronunciations. But no matter how sophisticated they made the word database, the machine still struggled to recognize even the most basic phrases. If a phrase is just a sequence of words, how can a machine that can recognize words NOT be able to recognize phrases? Good question. Let’s Google it… The reason this approach failed so miserably was because it didn’t account for the intrinsic ambiguity of language. When you analyze the acoustics of speech, you find that we're never consistent in the way we say things. A single meaning will be attached to a large number of distinct sound sequences, and a single sound sequence will have a variety of different meanings attached to it.
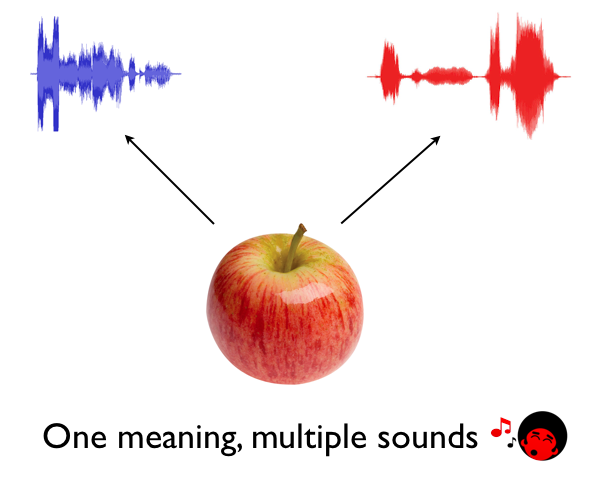

The recording below is a good demonstration of this:
I am intending to say the letters “N-Y-C,” but in a different context one could interpret these exact same sounds to mean something else. In fact, the original context for these sounds was the phrase “And I see you have a sister.”
Computers hate ambiguity, because they only know how to work with precise data. The sound profile of “N-Y-C” has a single physical reality to it and thus can only have a single interpretation to it as well. A computer can’t decide to interpret the same sound sequence to mean “NYC” one day and “and I see” the next. Or can it?
The Google Approach to Speech Recognition
Remember back when Google had a free 411 service? You could call in and ask for movie showtimes or restaurant listings and the automated voice would analyze your speech, plug it into the Google search engine, then return an answer to you. Turns out the reason they offered this service for free was because they were secretly recording each and every one of these interactions in order to “teach” the speech recognition software that now operates on every Android device. If I called in and said “N-Y-C” the same way I did in the recording above, Google would analyze the sound sequence just like the old machines, but instead of trying to get it right on the first try, it would simply make a random guess and ask the user for feedback.
“I think you said ‘and I see,’ is that correct?”
If I responded“no” – that specific guess would be downvoted within their system. If I say “yes,” the guess would be upvoted within the system. Repeat this trial-and-error game billions of times in billions of different context and eventually the higher probability choices emerge to the top, and Google starts to get really good at guessing the right answer on the first try. It won’t work 100% of the time, but if you’ve ever tried to transcribe a message on an Android phone you’ll know that it is impressively accurate. It’s at least waaay better than those crappy automated customer support machines that make you want to throw your phone into a river.
Operator: I think you said you want to hear your account balance. Is that correct? Please say yes or no You: Nooooo Operator : I’m sorry, I didn’t get that, please try calling back later
You: GAAAAH!!!
Comparing the Two Approaches in Computers and Humans
The original approach to speech recognition is the exact same as the traditional approach to language learning. Typically, language learners focus first on growing their database of vocabulary, then they try to deconstruct spoken phrases into the component words they know. Unsurprisingly, the approach is as ineffective for humans as it is for computers.
You can know all the vocabulary and grammar in the world, but if you can’t place these words in a real context, then you won’t be able to link “what you know” with “what you’re hearing.” In other words, knowing words in isolation is not enough to recognize them in real speech. The Google approach is much closer to how we naturally process language. Just like Google, we don’t rely solely on the sound inputs to make sense of what someone is saying to us; we consider the context as well. Think back on that “NYC” example again.
The first time Google heard a user say this phrase, it had no idea what the person was saying, so it just flipped a coin and guessed. But after guessing and storing millions of upvotes and downvotes, it starts to pick up on contextual patterns for this sound sequence. For example, it might find that there’s a 93.7% chance that the user is saying “N-Y-C” when it follows the word “Brooklyn.”
You: Google…Pizza restaurants in Brooklyn, NYC Google: “Did you say ‘N-Y-C?´ Actually you know what- forget I even asked. I KNOW that's what you said SUCKA!”
As Google becomes more familiar with different contexts, it starts to make fewer random guesses and more informed judgments. Our brains make the same sort of context-calculations all the time. If I called you right now and said: “I’m flying into ‘and I see' this weekend for a conference,” you’d most likely hear me say: “I’m flying into NYC this weekend for a conference.” Even if I articulated “and I see” slightly more clearly, there’s still a good chance you wouldn’t notice because it simply doesn’t fit in the context. Next time you’re waiting at a bus stop, point to your watch and ask the stranger next to you:
“Excuse me sir, you know what ramen is?”
Nine times out of of ten, he'll respond with the time:
“Yeah – my watch says half past noon.”
Just like Google, the stranger at the bus stop makes snap judgments based on context and experience. This is why when learning a foreign language, the most important thing is that you collect as many contexts as possible. Don't become obsessed with accumulating as many vocabularies as possible like some sort of flash card hoarder. Plop yourself in the middle of the language environment right from the beginning and hit up all the locals Google 411 style! This is what Benny is getting at with his Speak from Day 1 philosophy. It doesn’t matter that you’re guessing wrong all the time in the beginning; all that matters is that you keep guessing over and over again. Eventually, you’ll start guessing right.
Duolingo and The Mimic Method – The Perfect 1-2 Punch
This sounds all nice and peachy on paper, but many of us know that entering a new language environment with zero background can be overwhelming. There are two reasons for this:
- You can’t process the sounds of a new language.
- You don’t know which contexts to prioritize.
The second problem is the one that most language learning courses address. You have no idea which contexts are most relevant within a language, so the course or teacher decides for you by leading you down what they consider to be the shortest path. Duolingo undoubtedly does the best job of this.
Duolingo shows you the shortest path by organizing contexts in the form of mini-lessons on a “skill tree”. It doesn’t explicitly teach you any grammar. Instead it steps aside and lets you guess, and the same way we 411 users provided Google with feedback with a simple “yes” or “no,” Duolingo provides us with feedback with a simple “DING!” 🙂 or “wamp wamp” 🙁 . But Duolingo doesn’t address the sound problem. Listen closely to the phrase below then try to mimic it (*Recording courtesy of RhinoSpike.com user Paratishpa):
Unless you happen to be a fluent speaker of Mongolian, this task will have been “overwhelming” for you because you can’t accurately perceive the raw sounds.
This is a serious problem, because the Google approach to language-learning is predicated on the ability to accurately process speech sound. If you can’t process the sounds than you can’t store the sounds. And if you can’t store the sounds then you won’t be able recognize the contexts when listening to native speech. This was never an issue for Google because processing and storing acoustic data is a pretty routine task for modern computers. Unfortunately, you can’t just look up the sound drivers for Mongolian or any other language on the web and download them directly into your brains via Bluetooth connection (and no- it won't work for USB either).
You can, however, train and dramatically improve your ability to process sound in a second language. It's just a question of listening closely, making your best guess, getting feedback on that guess, then repeating the process over and over again.
This is exactly what the Mimic Method app will do for you if you “Fund the Flow” and help us realize our Kickstarter project. We will equip you with the tools to tune your ear to the finer nuances of the sounds, empower you to take your best guess, then give you precise and personalized feedback on this guess so you know exactly what you need to adjust. The the same way Duolingo makes the context-training experience fun and addictive by gamifying it with rewards and cartoon birds in different clothing, we make the sound-training experience fun and rewarding by funkifying it with music and singing ‘afrovatars’ in different hats!

Indeed, Duolingo is the best app out there for learning what stuff means in your target language, and once it’s been fully funded and realized, The Mimic Method app will be the best app out there for learning how stuff sounds in your target language. That’s why we decided to design a pronunciation training program specifically for users of the Duolingo app.
The idea is for you to accelerate the learning process even more by enabling you to attack these two problems simultaneously using similar content. I encourage you to check out our Kickstarter page and support the project. Like Duolingo, The Mimic Method app will be free once it's up and running, but only backers will receive the personalized training.
If you learn the meanings with Duolingo, master the sounds with The Mimic Method, and collect the context by putting yourself out there Benny Lewis-style, you’ll achieve fluency in your next language faster than you could with any other system. Don't believe me? Just Google it 😉
Social